What's the Real Difference Between AI-Dedicated and General-Purpose Tunnels? It's More Than Marketing
"AI-dedicated tunnel" sounds like something the marketing team invented, but it actually has three hard technical differences from general-purpose secure tunnels: routing strategy shifts from "shortest path" to "AI service optimal path," connection strategy from "random reconnection" to "session keepalive," and encryption from "TLS only" to "AES-256 end-to-end encryption." This article breaks down each difference and provides a practical comparison table for your selection.
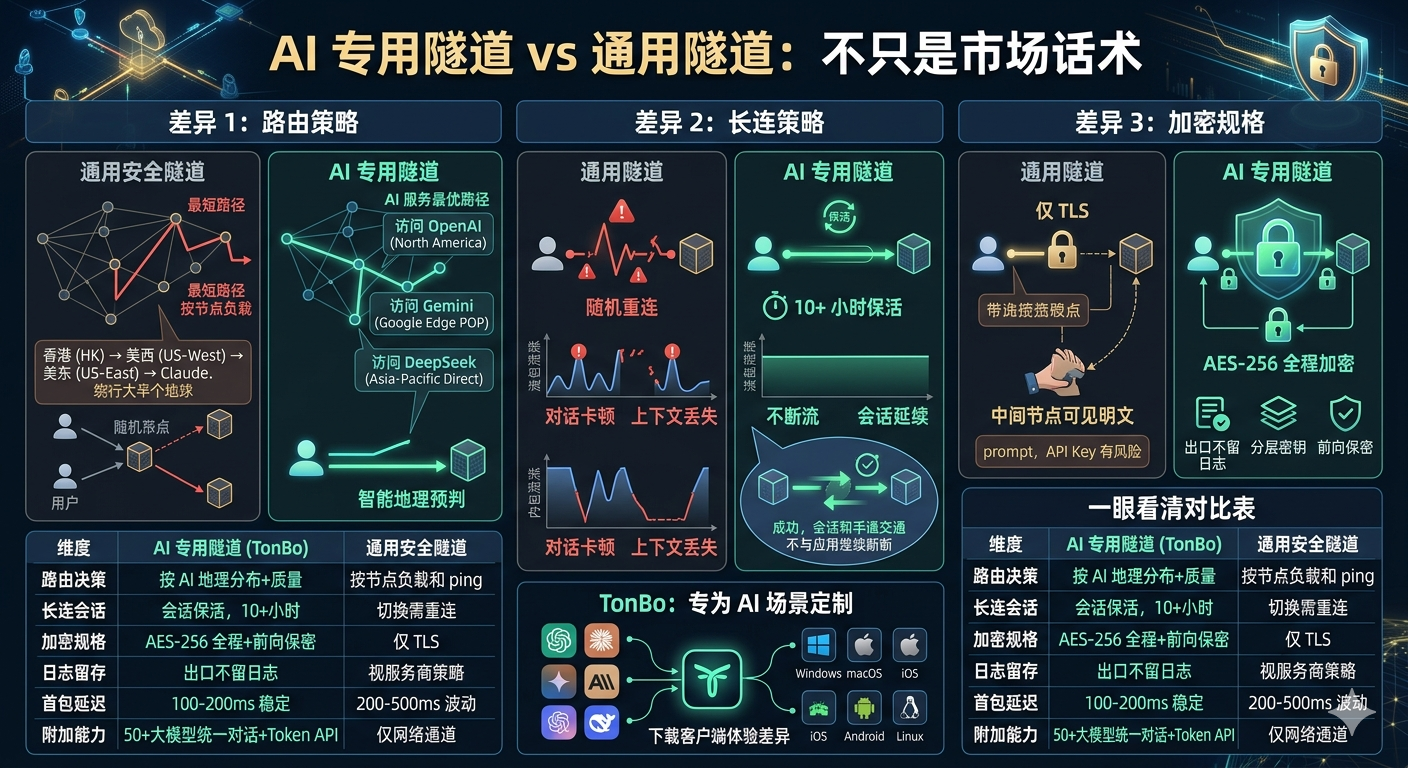
Difference 1: Routing Strategy from "Shortest Path" to "AI Optimal Path"
General-purpose secure tunnels use simple routing logic—find the node closest to the user with the lowest load. But "closest" doesn't mean "fastest access to Claude," because Anthropic's main inference clusters are in North America, and users in Asia routing through the nearest node actually have to circle halfway around the globe. AI-dedicated tunnels move this geographic intelligence to the ingress layer.
General-Purpose Tunnels Only Check Node Health
When a user in Asia initiates a request, a general-purpose tunnel picks the node with the lowest ping (like Hong Kong or Tokyo). But the return path from that node to Claude's servers isn't direct—it might go Japan → US West → US East → Anthropic exit, adding 3 extra hops in between.
AI-Dedicated Tunnels Consider AI Provider Geography
TonBo's routing decision synthesizes three factors: client location, AI provider's main inference cluster location, and real-time packet loss and latency on the current path. Access to OpenAI prioritizes exits nearest to US West, access to DeepSeek prioritizes Asia-Pacific internal circulation, access to Gemini prioritizes direct Google POP connections. The entire process is transparent to users, but creates a noticeable difference in first-packet latency and stability.
Difference 2: Connection Strategy Designed for Agent Loops
The network traffic characteristics of conversational AI and Agent tasks are completely different from ordinary web traffic—a single call can last minutes, and Agent loops can run for hours. General-purpose tunnels' long-connection mechanisms are designed for low-intensity scenarios like SSH and remote desktop, and expose numerous shortcomings in AI scenarios.
Conversational Traffic Is Extremely Sensitive to Disconnections
Streamed tokens arrive at millisecond granularity. Any TCP connection interruption causes the frontend interface to freeze and token streams to roll back, making users feel like "the AI is stuck." General-purpose tunnels disconnect directly when encountering mid-node switching (like load balancer auto-scheduling), forcing clients to reconnect and losing the current conversation context.
Session Keepalive and Heartbeat: Agent Streams for 10+ Hours Without Interruption
AI-dedicated tunnels implement three things at the ingress layer: first, session keepalive that maintains a single stream for 10+ hours; second, heartbeat probing that actively switches exit nodes when the path is abnormal but remains transparent to the application layer; third, automatic reconnection with context preservation, so even brief reconnections don't invalidate the Agent's session token in extreme cases.
Difference 3: Encryption Specifications Protect Prompts and API Keys
When you paste internal documents into ChatGPT, run data analysis in Claude, or pass API Keys in Token API—this data often contains corporate secrets. General-purpose tunnels only encrypt the "user → ingress point" segment with TLS; what protocol is used between ingress and exit points and whether it's encrypted is invisible to users.
AES-256 End-to-End Encryption + No Log Retention
AI-dedicated tunnels apply AES-256 encryption between the ingress layer and exit nodes, stacking on top of user-side TLS to create dual-layer encryption. Exit nodes don't retain request logs—meaning even if an exit node is compromised, attackers can't access historical prompts and API Keys.
Layered Key Management and Forward Secrecy
Each session's encryption key is temporarily generated and destroyed when the session ends. Even if a long-term master key is compromised in the future, historical sessions cannot be replayed. This feature is especially important in "compliance-sensitive" enterprise scenarios.
At a Glance: AI-Dedicated Tunnel vs. General-Purpose Solution
| Dimension | AI-Dedicated Tunnel (TonBo) | General-Purpose Secure Tunnel |
|---|---|---|
| Routing Decision | Based on AI provider geography + real-time path quality | Based on node load and ping value |
| Long Connection Session | Session keepalive, 10+ hours without interruption | Node switching requires reconnection |
| Encryption Specification | AES-256 end-to-end + forward secrecy | TLS only |
| Log Retention | Exit nodes don't retain request logs | Depends on provider policy |
| First-Packet Latency | 100-200ms stable | 200-500ms fluctuation |
| Additional Capabilities | 50+ LLM unified conversation + Token API | Network channel only |
When to Use AI-Dedicated Tunnel vs. General-Purpose Solution
- You primarily use AI tools: AI-dedicated tunnel offers much better value, with subscription including tunnel + conversation + Token API
- You occasionally use AI, mainly do other access: General-purpose solution is sufficient, AI experience is mediocre
- You're developing Agents: AI-dedicated tunnel is almost the only choice, with long-connection stability orders of magnitude better
- You're extremely privacy-sensitive: AES-256 end-to-end encryption and exit nodes that don't retain logs are hard requirements
Choose the Right Tunnel, Keep Your AI Conversations Connected
Not all "secure tunnels" are suitable for AI traffic. TonBo is a secure tunnel custom-built for AI scenarios, with subscription including 50+ LLM unified conversation and OpenAI-compatible Token API. Download the client to try for free and experience the differences brought by routing strategy, connection strategy, and encryption specifications.