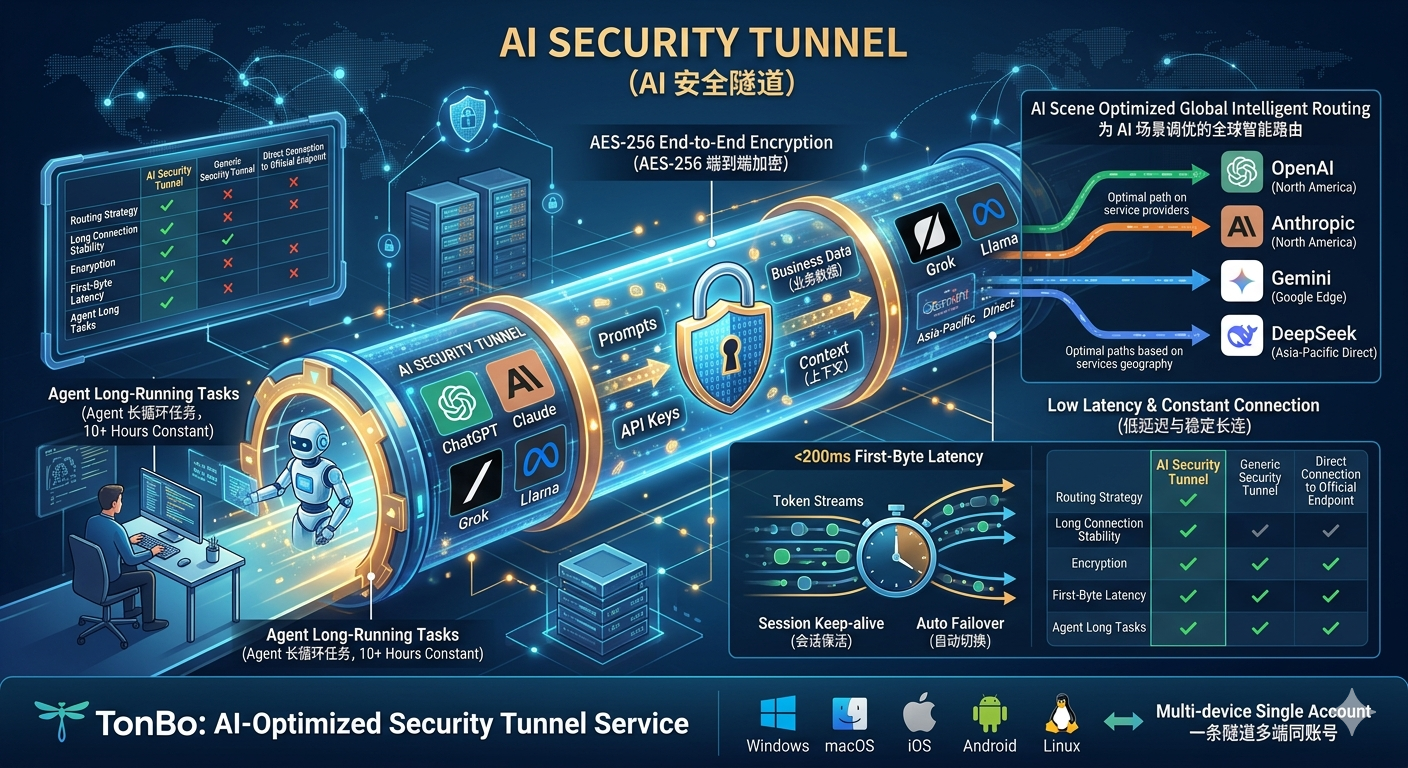
AI Security Tunnel: An Encrypted Network Channel Customized for Large Language Model Calls
An AI security tunnel is an AES-256 encrypted network channel customized for large language model calls like ChatGPT, Claude, Gemini, Grok, and Llama. It differs fundamentally from traditional general-purpose security tunnels: the former predicts optimal paths based on AI service provider geographic distribution, maintains long-lived connections for Agent loop tasks, and provides end-to-end encryption for prompts and API Keys; the latter only cares about "the shortest distance between two points." This article clarifies the three key capabilities of AI security tunnels and their practical differences from general solutions.
If you've ever experienced a ChatGPT stream suddenly cutting off mid-response, or a Claude Agent task failing after running for several hours only to lose all context, the root cause usually isn't the model itself—it's the network layer underneath. Most general-purpose network solutions were designed for web browsing and file transfers, not for the sustained, low-latency, encryption-sensitive traffic patterns that large language model calls demand. Understanding what an AI security tunnel actually does—and why it's architecturally different—is the starting point for fixing these problems at the source.
Why AI Scenarios Need a Dedicated Tunnel
Streaming video, editing collaborative documents, sending emails—these requests have small average payloads, high latency tolerance, and brief disconnections are barely noticeable to users. But AI conversations, model inference, and Agent loops are entirely different traffic patterns—first-packet latency determines user experience, long connection interruptions mean the entire context must restart, and prompts often contain API Keys and business data. General-purpose security tunnels are optimized for ordinary web traffic and often don't fit well in AI scenarios.
1. Network Characteristics of Large Language Model Calls Are Completely Different from Ordinary Requests
A single GPT-5 conversation can last over 30 seconds, with tokens streamed back to the client at 100-200ms granularity. Any TCP connection fluctuation in between causes the frontend interface to stall or drop the stream entirely. Agent tasks are even more extreme—a long loop might run for 10 hours and pull hundreds of model responses. General-purpose tunnels charge by "number of accesses" and don't care about individual connection lifecycles, leading to repeated handshakes and frequent packet loss retransmissions in AI scenarios.
2. First-Packet Latency Is a Hard Metric for Conversational AI
When users click "send," they expect to see the model start outputting within 300ms. This 300ms window must cover DNS resolution, TLS handshake, and the model provider's inference warmup. Any additional hops or path switches will exceed this window. AI security tunnels move DNS and routing decisions to the ingress layer, keeping first-packet latency stable within acceptable user ranges.
3. Agent Long-Loop Tasks Require Stable Long Connections
Agent workflows routinely contain dozens of model calls, tool calls, and external API requests. Any tunnel reconnection can invalidate session tokens and lose conversation context. AI security tunnels use session keepalive, heartbeats, and automatic failover to ensure long tasks lasting 10+ hours don't drop.
4. Cross-Region Traffic Routing Is Not a One-Size-Fits-All Problem
Different AI service providers have different geographic footprints. Anthropic's API endpoints are concentrated in North America; Google's Gemini inference infrastructure leans on its own edge network; DeepSeek's nodes are primarily Asia-Pacific. A general-purpose tunnel picks the "nearest exit" without any awareness of where the destination service actually lives. This mismatch can add 100-300ms of unnecessary round-trip latency simply because the tunnel exits in the wrong region for that particular provider.
An AI security tunnel solves this by maintaining a continuously updated map of AI provider ingress geography. When you send a request to Claude, the tunnel routes you through a North American exit; when you switch to DeepSeek in the same session, the routing layer silently adjusts without requiring you to manually switch nodes. For developers running multi-model comparison workflows—calling GPT-5, Claude 3.5, and Gemini 1.5 Pro in the same script—this provider-aware routing is the difference between a smooth benchmark run and a frustrating series of timeouts.
Three Key Capabilities of AI Security Tunnels
1. Global Intelligent Routing Optimized for AI Scenarios
TonBo's intelligent routing dynamically selects paths based on the actual ingress point distribution of AI service providers. For example: accessing Anthropic primarily uses North American nodes, accessing Gemini prioritizes Google edge nodes, accessing DeepSeek uses Asia-Pacific direct connections. Routing decisions aren't made on the client side but at the ingress layer using real-time node health data, historical latency, and service provider geography for comprehensive scoring.
2. AES-256 End-to-End Encryption Protecting Prompts and API Keys
AI conversations often contain business data, user privacy, API Keys, and tokens. Standard TLS only protects the "user-to-ingress-point" segment; data may still be visible in plaintext after the ingress point. AI security tunnels apply AES-256 encryption between the ingress layer and egress nodes, with multiple encryption layers providing forward secrecy so that even if one segment's key is compromised, historical data cannot be replayed.
This matters especially for enterprise users who embed internal knowledge base content directly into prompts, or for developers whose API Keys represent significant billing exposure. A compromised key on a shared or unencrypted intermediate node can result in unauthorized API usage that doesn't surface until the monthly bill arrives. The end-to-end encryption model in an AI security tunnel ensures that no intermediate hop—including the tunnel operator's own infrastructure—can read prompt content in transit.
3. One Tunnel, Multiple Devices, Same Account
A single TonBo account can be online simultaneously across Windows, macOS, iOS, Android, and Linux. Common developer workflows—local debugging, server-side batch processing, mobile result checking—can all run on the same tunnel, with unified traffic billing and naturally continuous sessions.
AI Security Tunnel vs. General-Purpose Network Solutions Comparison
| Dimension | AI Security Tunnel | General-Purpose Security Tunnel | Direct Official Endpoint |
|---|---|---|---|
| Routing Strategy | Proactively predicts based on AI provider geography | Simple scheduling by node load | Entirely dependent on ISP |
| Long Connection Stability | Session keepalive + heartbeat + automatic failover | Requires manual reconnection on disconnect | ISP throttling / packet loss |
| Encryption Spec | AES-256 end-to-end + forward secrecy | TLS only | TLS only |
| First-Packet Latency | Stable 100-200ms | 200-500ms fluctuation | Frequently exceeds 500ms |
| Agent Long Tasks | 10+ hours without interruption | Requires frequent reconnection | Not guaranteed |
| Provider-Aware Routing | Yes — per-provider optimal exit selection | No — single exit for all destinations | No — fixed ISP path |
| Multi-Device Same Account | Windows / macOS / iOS / Android / Linux simultaneous | Varies by provider, often limited | Not applicable |
| Prompt Data Protection | AES-256 full path, no plaintext at intermediate nodes | TLS terminates at ingress, plaintext risk beyond | TLS only, ISP path visible |
Who Benefits from AI Security Tunnels
- AI Content Creators: Using GPT-5, Claude, and Gemini simultaneously for comparative creation, wanting seamless model switching
- Agent Developers: Running long-loop automation workflows with extreme requirements for long connection stability
- Researchers: Running batch evals, retrospectives, and comparative experiments, needing low-latency stable throughput
- Cross-Border Collaboration Teams: Members distributed across multiple locations, needing simultaneous multi-device online access with the same account
- Privacy-Sensitive Enterprise Users: Prompts contain internal business data and shouldn't be visible to intermediate nodes
Common Questions About AI Security Tunnels
Is an AI security tunnel the same as a regular VPN?
Not architecturally. A conventional VPN routes all your traffic through a single exit node, applying the same logic to a Netflix stream and a Claude API call alike. An AI security tunnel is purpose-built for large language model traffic: it maintains provider-specific routing tables, uses session keepalive mechanisms designed for streaming inference responses, and applies encryption at the application layer rather than just the transport layer. The practical difference shows up in first-packet latency and long-connection stability—two metrics that conventional VPNs don't optimize for at all.
Will using an AI security tunnel slow down my model responses?
On a well-architected AI security tunnel, the answer is usually the opposite. The latency cost of the tunnel's encryption and routing overhead is typically 10-20ms, which is more than offset by the routing improvement from sending your request through a geographically optimal exit rather than whatever path your ISP happens to prefer. Users who previously experienced first-packet latency above 500ms on direct connections often see it drop significantly after switching to a provider-aware tunnel. That said, no tunnel eliminates the model provider's own inference time—that component is fixed regardless of your network path.
How does an AI security tunnel protect my API Keys specifically?
API Keys are transmitted as HTTP headers in every request to OpenAI, Anthropic, Google, and similar providers. On a standard TLS connection, the key is encrypted between your device and the first server it reaches—but if that server is a shared intermediate node, the key may be logged or visible in plaintext at that hop. An AI security tunnel with AES-256 end-to-end encryption ensures the key remains encrypted all the way to the egress node closest to the AI provider's own infrastructure, with forward secrecy ensuring that past traffic can't be decrypted even if a future key is compromised.
Can I use one account across my laptop, phone, and a cloud server simultaneously?
With TonBo, yes. A single subscription covers simultaneous connections across Windows, macOS, iOS, Android, and Linux. This matters for developers who run local prototyping on a MacBook, batch inference jobs on a Linux cloud instance, and check results on an iPhone—all three can share the same tunnel session with unified traffic accounting. You don't need separate accounts or separate billing for each device.
What happens to my Agent task if the tunnel has a brief interruption?
TonBo's session keepalive and automatic failover mechanisms are specifically designed to handle this scenario. When a node becomes temporarily unreachable, the tunnel switches to a backup path without tearing down the application-layer session. For most Agent frameworks, this means the long-loop task continues without the session token being invalidated. Complete node failures lasting more than a few seconds are the edge case where context loss remains a risk—which is why Agent developers are also advised to implement checkpoint logic at the application layer as a secondary safeguard.
Download TonBo and Experience AI Security Tunnels Now
TonBo is a security tunnel service customized for AI scenarios, with subscriptions including unified conversations with 50+ large language models and OpenAI-compatible Token API. All AI traffic runs on the same tunnel with AES-256 encryption, global intelligent routing, and low-latency long connections. Download the client to use it across Windows / macOS / iOS / Android / Linux platforms.
Whether you're an independent creator switching between models mid-project, a developer running overnight Agent pipelines, or a team with members spread across multiple time zones, the underlying network layer is the part of your AI workflow that's easiest to overlook and most disruptive when it fails. An AI security tunnel purpose-built for large language model traffic is the infrastructure layer that keeps everything else running reliably.