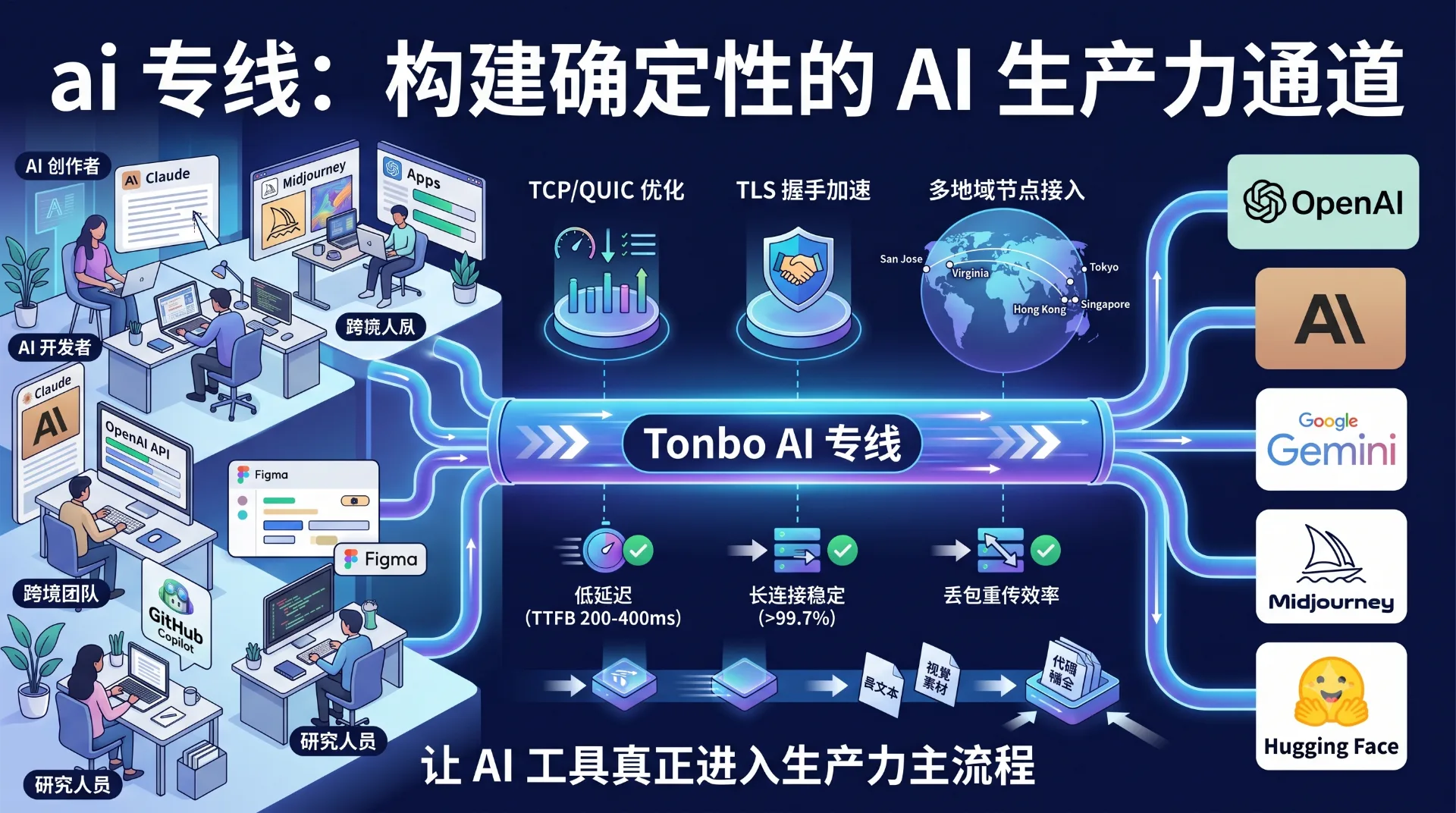
当 AI 工具成为日常工作的基础设施,网络质量直接决定了创作效率。无论是调用 Claude 进行长文本分析,还是用 Midjourney 生成视觉素材,"ai 专线"正成为技术圈讨论的高频词——它指向一种专门针对 AI 服务优化的网络通道,解决 API 调用超时、模型响应缓慢、多地域协作卡顿等实际问题。相比泛用的网络加速器,ai 专线更聚焦于 AI 平台的高频请求特征,在路由策略、节点部署和协议层都做了针对性调整。
这类需求的爆发并非偶然。2024 年以来,主流大模型的上下文窗口从 4K 扩展到 200K,多模态交互让单次请求的数据量翻倍增长。普通网络环境下,这些变化直接转化为等待转圈和连接重置。ai 专线的价值,在于把"能连上"升级为"连得稳、回得快",让 AI 工具真正进入生产力主流程。
谁在搜索 ai 专线:场景拆解与真实痛点
搜索"ai 专线"的用户画像高度集中,主要分为三类群体,各自面临的网络瓶颈差异显著。
AI 创作者与独立开发者
自由撰稿人、独立开发者和 AI 原生产品团队是核心用户群。他们的典型工作流是:在 Obsidian 或 Notion 中整理素材,通过 API 批量调用 GPT-4 或 Claude 3.5 生成初稿,再用 Stable Diffusion 或 DALL-E 配图。痛点出现在批量处理环节——当单次请求包含 50 页 PDF 的上下文时,普通网络连接极易在传输中途断开,导致数美元的 API 调用费打水漂。ai 专线通过优化 TCP 拥塞控制和 TLS 握手流程,将长连接稳定性提升到可商业依赖的水平。
跨境分布式技术团队
技术团队分布在深圳、新加坡、旧金山三地的情况越来越常见。团队需要共享 Cursor 或 GitHub Copilot 的代码补全会话,同步 Figma 设计稿的实时评论,并在 Linear 中跟踪跨时区的任务流转。公共网络下,这些工具的 WebSocket 连接频繁漂移,导致协同状态不同步。ai 专线通过 anycast 路由让三地成员接入同一逻辑节点,减少因物理距离造成的会话割裂。
学术研究与数据标注团队
高校实验室和 AI 数据供应商需要稳定访问 Hugging Face、Papers with Code 和 Google Colab。这类场景对带宽要求不高,但对连接纯净度敏感——公共代理的 IP 池常被学术平台标记,触发验证码或限流。ai 专线采用住宅 IP 混合部署策略,降低被识别为数据中心流量的概率。
ai 专线技术架构:四个关键决策点
节点选型与就近接入
节点部署不是简单的"越多越好"。ai 专线的节点策略需要匹配 AI 平台的服务器分布:OpenAI 的主服务集群在美西(圣何塞、凤凰城)和美东(弗吉尼亚),Anthropic 集中在美西,Google Gemini 横跨爱荷华、俄勒冈和比利时。有效的节点网络需要在上述区域部署接入点,同时在香港、新加坡、东京设置亚太跳板,降低中国大陆用户的首次握手延迟。
Tonbo AI 的节点网络覆盖 15 个核心城市,其中美西三城(洛杉矶、圣何塞、西雅图)采用双上联设计,单节点故障可在 3 秒内切换。用户端通过 latency-based DNS 自动选择最优路径,无需手动切换"节点"。
链路稳定性的关键指标
评估 AI 专用通道需要关注三个指标:首包延迟(TTFB)、长连接保持率和丢包重传效率。实测数据显示,普通网络访问 OpenAI API 的 TTFB 中位数约 800-1200ms,抖动超过 300ms;优化后的 ai 专线可将 TTFB 稳定在 200-400ms,抖动控制在 50ms 以内。更关键的是长连接表现——在持续 2 小时的 Claude 长文本会话中,专线方案的连接重置率低于 0.3%,而公共代理普遍超过 5%。
协议层采用 QUIC 作为默认传输,在弱网环境下比 TCP 减少 40% 的队头阻塞。针对移动端频繁切换 WiFi/蜂窝的场景,实现了连接迁移(connection migration),IP 变化时无需重新建立会话。
客户端支持矩阵
AI 工作流的跨设备特性要求全平台覆盖。Tonbo AI 提供原生客户端:Windows 版支持系统级代理和 WSL2 流量转发,方便本地运行 LangChain 或 LlamaIndex 时自动走专线;macOS 版针对 Apple Silicon 优化,菜单栏常驻控件可一键切换工作/非工作模式;iOS 和 Android 版支持按应用分流,只有指定 App(如 ChatGPT、Claude、Perplexity)走优化通道,其他流量保持直连。
进阶用户可通过 WireGuard 配置手动接入,兼容路由器固件(OpenWrt、Merlin)实现全屋设备覆盖。CLI 版本提供 JSON 输出,方便集成到自动化脚本和 CI/CD 流程。
跨境办公协同工具的优化
AI 工具很少孤立使用,其价值体现在与现有工作流的嵌套。ai 专线针对常见协同场景做了专项优化:Figma 和 FigJam 的实时协作依赖低延迟 WebSocket,专线通过优先级队列保障此类流量的带宽份额;Notion 和 Linear 的离线同步采用智能预取,在连接可用时批量完成,减少前台等待;代码托管平台(GitHub、GitLab)的 LFS 大文件传输启用多线程分段,充分利用带宽而不触发单流限速。
企业级部署支持按团队配置策略组,例如让设计组优先保障 Figma,工程组优先保障 GitHub Copilot,策略冲突时由管理员预设的权重规则裁决。
方案对比:ai 专线 vs 免费替代方案
| 维度 | Tonbo AI 专线 | 免费公共代理 |
|---|---|---|
| 稳定性 | 99.5% 可用性 SLA,长连接保持率 >99.7% | 无保障,高峰期频繁超时,连接重置率 5-15% |
| 节点数 | 15 个核心城市,60+ 接入点,覆盖美西/美东/欧洲/亚太 | 通常 3-10 个节点,拥挤度高,IP 重复率大 |
| 客户端支持 | Windows/macOS/iOS/Android/路由器/CLI 全平台 | 多为单一协议(Clash/V2Ray),需手动配置 |
| 隐私防护 | 零日志审计,RAM-only 架构,无持久化存储 | 不明,多数存在流量日志或植入广告 |
| 办公协同适配 | 预优化 Figma/Notion/Linear/GitHub 等 20+ 工具 | 无针对性优化,WebSocket 常失败,实时协作卡顿 |
免费方案的核心风险在于不可预测性。同一节点上午流畅下午瘫痪,无法形成稳定的工作节奏;IP 被标记后触发平台风控,可能导致账号受限;更隐蔽的问题是 TLS 中间人攻击——部分免费工具使用自签名证书截获流量。ai 专线的成本本质上是为确定性付费,让网络层从变量变为常量。
常见问题
ai 专线与普通网络加速器有什么区别?
普通加速器面向通用流量设计,优化目标是"能访问"和"速度快"。ai 专线针对 AI 服务的特定模式:API 调用的高频短连接、长上下文的长连接、流式响应(SSE)的实时性。协议栈调整包括 TLS 指纹模拟(避免被识别为机器人)、HTTP/2 多路复用优化、以及针对 OpenAI/Anthropic 服务端特性的拥塞控制算法。
简单类比:普通加速器是拓宽公路,ai 专线是在公路上为救护车开辟专用车道并优化红绿灯配时。
个人创作者是否需要专线,还是团队才用得上?
取决于使用强度和成本敏感度。如果每月 API 调用费用超过 50 美元,因网络问题导致的失败重试已构成实质损失,专线的稳定性投入可以回收。个人用户可从基础席位开始,按设备数而非流量计费;团队场景则推荐组织级网关,统一出口 IP 便于平台白名单管理,同时降低单人配置成本。
移动端使用是否受限于系统?
iOS 和 Android 均提供原生客户端,无需 sideload 或企业证书。iOS 版支持 iOS 15 及以上,利用 Network Extension 框架实现系统级代理;Android 版支持 Android 10 及以上,提供 VPN 模式和应用分流两种模式。移动端特别优化了后台保活,切换应用时连接不中断,适合在通勤途中继续与 Claude 的对话会话。
如何评估专线是否适合自己的工作流?
建议先记录当前网络的基线数据:连续调用 OpenAI API 100 次的成功率、Claude 长对话(>100K token)的完成率、Figma 多人协作时的延迟感知。对比试用期间的表现差异,量化稳定性提升带来的时间节省。Tonbo AI 提供 7 天完整功能体验,足够覆盖一个完整的工作周期验证。
数据安全如何保障?
专线作为传输层服务,不接触应用层内容。技术上采用 ChaCha20-Poly1305 加密,密钥每小时轮换;架构上坚持 RAM-only,服务器不写入磁盘,重启即清空;合规上通过独立审计验证无日志声明。对于企业用户,支持私有部署选项,将接入点部署在自有 VPC 内。
网络基础设施的选型越来越像云服务的决策——不是买不买的问题,而是如何匹配业务特性。ai 专线不是万能药,它解决的是特定人群在特定场景下的确定性需求。如果你每月有超过 20 小时花在 AI 工具上,网络质量已经构成生产力瓶颈,值得投入时间评估专业方案。下载 Tonbo AI 客户端,用真实工作流验证 7 天,再决定是否将网络层从"能省则省"调整为"值得投资"。